The damped, periodically-kicked rotator is one of the simplest dynamical systems that displays chaotic behavior1.
Below we find the equation of motion of the damped, kicked rotator
$$\ddot{\phi} + \Gamma\dot{\phi} = F = Kf(\phi)\sum_{n=0}^{\infty}\delta(t – nT) \tag{1}$$
where $n$ is an integer, dots denote time derivatives, $\Gamma$ is the damping constant, and $T$ is the period of time that elapses between successive force impulses or "kicks". Variable $\phi$ is a canonical coordinate denoting the angular position of the rotator at time $t$. The moment of inertia of the rotator has been normalized to unity.
If we make the substitutions
$$x=\phi, y=\dot{\phi}, z=t$$
the single, second-order equation of motion of one variable can be written as a system of three first-order, autonomous differential equations
\begin{align}
\dot{x} &= y \tag{2a} \\
\dot{y} &=-\Gamma y + Kf(x)\displaystyle\sum_{n=0}^{\infty}\delta(z – nT) \tag{2b} \\
\dot{z} &= 1 \tag{2c}.
\end{align}
Schuster asserts that the three equation system above $(2a,b,c)$ can be reduced to the two-dimensional map
We will begin with equation $(2b)$ above. First, we bring the sum to the left to contain $f(x)$ and then substitute the function $x(mT-\varepsilon)$ for $x$. Notice we’re adopting a new dummy indexing variable $m$ since $n$ is used in the integration limits.
Next we will mulitiply both sides of the equation by $e^{\Gamma t’}$ and then integrate by parts, with respect to $t’$, between limits from $nT-\varepsilon$ to $t$
$$ \int_{nT-\varepsilon}^{t}\left(\frac{\mathrm{d}}{\mathrm{d}t’}y(t’)\right) e^{\Gamma t’} dt’ = -\int_{nT-\varepsilon}^{t} \Gamma y(t’) e^{\Gamma t’} dt’ + K \int_{nT-\varepsilon}^{t} \sum_{m=0}^{\infty} f(x(mT-\varepsilon)) \delta(t’-mT) e^{\Gamma t’} dt’ \tag{3}$$
Evaluating the definite integral on the LHS of equation $(3)$ we perform integration by parts selecting
$u = e^{\Gamma t’}$ so that $du = \Gamma e^{\Gamma t’} dt’$ leaving $dv = \left(\frac{\mathrm{d}}{\mathrm{d}t’}y(t’)\right) dt’$ so that $v = y(t’)$. Recall that $\int u dv = uv – \int vdu$, so it follows that
$$ \int_{nT-\varepsilon}^{t}\left(\frac{\mathrm{d}}{\mathrm{d}t’}y(t’)\right) e^{\Gamma t’} dt’ = e^{\Gamma t’} y(t’)\rvert_{t’=nT-\varepsilon}^{t’=t} – \int_{nT-\varepsilon}^{t}\Gamma y(t’)e^{\Gamma t’}dt’ \tag{4}$$
Notice that the last term on the RHS of $(4)$ exactly matches the first term on the RHS of $(3)$. We can thus subtract these out on writing the equality. We next evaluate the first term on RHS of $(4)$ at the integral limits and then rearrange and divide by $e^{\Gamma t}$. Leaving us with
$$ y(t) = e^{\Gamma (nT-\varepsilon – t)} y(nT-\varepsilon) + K \int_{nT-\varepsilon}^{t} \sum_{m=0}^{\infty} f(x(mT-\varepsilon)) \delta(t’-mT) e^{\Gamma (t’-t)} dt’ \tag{5}$$
And finally, turning our attention to the remaining integral term on RHS of equation $(5)$, since $f(x(mT-\varepsilon))$ in no way depends on $t’$, the integration variable, the integral can be expressed
$$ K \int_{nT-\varepsilon}^{t} \sum_{m=0}^{\infty} f(x(mT-\varepsilon)) \delta(t’-mT) e^{\Gamma (t’-t)} dt’ = K \sum_{m=0}^{\infty} f(x(mT-\varepsilon)) \int_{nT-\varepsilon}^{t} \delta(t’-mT) e^{\Gamma (t’-t)} dt’ \tag{6}$$
To evaluate the RHS of equation $(6)$ above, we integrate noticing that the integrand contains the Dirac delta function as a factor
$$ K \sum_{m=0}^{\infty} f(x(mT-\varepsilon)) \int_{nT-\varepsilon}^{t} \delta(t’-mT) e^{\Gamma (t’-t)} dt’ = K f(x(mT-\varepsilon)) e^{\Gamma(mT-t)} \tag{7}$$
when $m=n$, and 0 when $m \neq n$. Writing out the sum is no longer necessary since only one non-zero term remains. After substituting $n$ for $m$ our complete expression now reads
$$y(t) = e^{\Gamma (nT-\varepsilon – t)} y(nT-\varepsilon) + K f(x(nT-\varepsilon)) e^{\Gamma (nT-t)} \tag{8}$$
We can make the substitution $ t \rightarrow (n + 1)T – \varepsilon $ to eliminate $t$ leaving
$$y((n + 1)T – \varepsilon) = e^{-\Gamma T} y(nT-\varepsilon) + K f(x(nT-\varepsilon)) e^{-\Gamma (T-\varepsilon)} \tag{9}$$
which, in the limit $ \varepsilon \rightarrow 0 $ becomes
$$ y_{n+1} = y_{n} e^{-\Gamma T} + K f(x_{n}) e^{-\Gamma T} \tag{10}$$
using variables $(x_n, y_n)$ defined above. After factoring the RHS
$$ y_{n+1} = e^{-\Gamma T} [y_{n} + K f(x_n)] \tag{11}$$
we are left with expression $(1.18a)$ of Schuster.
To derive the other equation of the two-equation map system (Schuster, $(1.18b)$), we integrate $ \dot{x} = y $ using equation $(11)$. That is,
$$\int_{0}^{T}y_{n+1} dT’ = \int_{0}^{T} e^{-\Gamma T’}[y_n + K f(x_n)] dT’ \tag{12}$$
Moving the bracketed factor outside of the integral, integrating and evaluating the result at the limits of integration we see that
$$\int_{0}^{T} e^{-\Gamma T’}[y_n + K f(x_n)] dT’ = [y_n + K f(x_n)] \int_{0}^{T} e^{-\Gamma T’} \tag{13}$$
and
$$ [y_n + K f(x_n)] \int_{0}^{T} e^{-\Gamma T’} = [y_n + K f(x_n)] \left(-\frac{1}{\Gamma}\right) e^{-\Gamma T’} \rvert_{T’=0}^{T’=T} \tag{14}$$
leaving us with
$$ [y_n + K f(x_n)] \left[ -\frac{1}{\Gamma} e^{-\Gamma T} – \left( – \frac{1}{\Gamma} \right) \right] = \frac{1 – e^{-\Gamma T}}{\Gamma} [y_n + K f(x_n)] \tag{15}$$
after algebraic simplification.
Given our original equation $(2a)$ in continuous form, $\dot{x} = y$, we can write its discrete analog as
$$ x_{n+1} – x_{n} = \int_{0}^{T} y_{n+1} dT’ \tag{16}$$
which implies the LHS of $(16)$ above equals the RHS of equation $(15)$
$$ x_{n+1} – x_{n} = \frac{1 – e^{-\Gamma T}}{\Gamma} [y_n + K f(x_n)] \tag{17}$$
and therefore
$$ x_{n+1} = x_{n} + \frac{1 – e^{-\Gamma T}}{\Gamma} [y_n + K f(x_n)] \tag{18}$$
which is equation $(1.18b)$ of Schuster.
The complete system of the damped, periodically-kicked rotator after reduction into a two-dimensional map of discrete variables
$(x_{n}, y_{n}) \triangleq \lim_{\varepsilon \rightarrow 0} [x(nT – \varepsilon), y(nT – \varepsilon)]$ is
Again, as stated in the text, equations $(19a, b)$ above
reduce the initial set of three-dimensional differential equations to a two-dimensional discrete map, which yields a stroboscopic picture of the variables.2
Schuster goes on to show how the Logistic, Hénon and Chirikov Maps can all be derived from this map system depending upon the particular set of limits imposed on it.
Lastly, by adding a constant torque to the driving force in equations $(19a, b)$ followed by a series of "simplifying substitutions", the one-dimensional Sine Circle Map can be derived3.
In this project we acquired graduation rate data on campuses within the California State University system using the Integrated Postsecondary Education Data System developed by the National Center for Education Statistics. Specifically, we obtained rates for students that graduated within 150% of normal graduating time for their particular Bachelor’s degree for years 2009 and 2019.
Below we investigate if there is a statistically significant change in graduation rates among CSU campuses recently (2019) as compared to ten years prior (2009).
Index(['unitid', 'institution name', 'year',
'GR200_19.4-year Graduation rate - bachelor's degree within 100% of normal time',
'GR200_19.6-year Graduation rate - bachelor's degree within 150% of normal time',
'GR200_19.8-year Graduation rate - bachelor's degree within 200% of normal time'],
dtype='object')
In [33]:
GR2009_df.columns
Out[33]:
Index(['unitid', 'institution name', 'year',
'GR200_09_RV.4-year Graduation rate - bachelor's degree within 100% of normal time',
'GR200_09_RV.6-year Graduation rate - bachelor's degree within 150% of normal time',
'GR200_09_RV.8-year Graduation rate - bachelor's degree within 200% of normal time'],
dtype='object')
GR200_09_RV.4-year Graduation rate – bachelor’s degree within 100% of normal time
GR200_09_RV.6-year Graduation rate – bachelor’s degree within 150% of normal time
GR200_09_RV.8-year Graduation rate – bachelor’s degree within 200% of normal time
coded names
0
110486
California State University-Bakersfield
2009
14.0
40.0
46.0
B
1
110495
California State University-Stanislaus
2009
19.0
52.0
57.0
Stan
2
110510
California State University-San Bernardino
2009
10.0
38.0
45.0
SB
3
110538
California State University-Chico
2009
15.0
52.0
57.0
C
4
110547
California State University-Dominguez Hills
2009
5.0
28.0
37.0
DH
5
110556
California State University-Fresno
2009
14.0
48.0
55.0
Fres
6
110565
California State University-Fullerton
2009
15.0
50.0
57.0
Full
7
110574
California State University-East Bay
2009
11.0
40.0
46.0
EB
8
110583
California State University-Long Beach
2009
10.0
47.0
57.0
LB
9
110592
California State University-Los Angeles
2009
10.0
31.0
39.0
LA
10
110608
California State University-Northridge
2009
9.0
41.0
49.0
N
11
110617
California State University-Sacramento
2009
10.0
42.0
50.0
Sac
12
111188
California State University Maritime Academy
2009
43.0
62.0
64.0
Mar
13
366711
California State University-San Marcos
2009
12.0
44.0
47.0
SM
14
409698
California State University-Monterey Bay
2009
12.0
36.0
41.0
MB
15
441937
California State University-Channel Islands
2009
NaN
NaN
NaN
CI
In [6]:
GR2019_df.info
Out[6]:
<bound method DataFrame.info of unitid institution name year \
0 110486 California State University-Bakersfield 2019
1 110495 California State University-Stanislaus 2019
2 110510 California State University-San Bernardino 2019
3 110538 California State University-Chico 2019
4 110547 California State University-Dominguez Hills 2019
5 110556 California State University-Fresno 2019
6 110565 California State University-Fullerton 2019
7 110574 California State University-East Bay 2019
8 110583 California State University-Long Beach 2019
9 110592 California State University-Los Angeles 2019
10 110608 California State University-Northridge 2019
11 110617 California State University-Sacramento 2019
12 111188 California State University Maritime Academy 2019
13 366711 California State University-San Marcos 2019
14 409698 California State University-Monterey Bay 2019
15 441937 California State University-Channel Islands 2019
GR200_19.4-year Graduation rate - bachelor's degree within 100% of normal time \
0 14
1 11
2 12
3 26
4 6
5 15
6 22
7 10
8 16
9 6
10 13
11 9
12 47
13 14
14 23
15 26
GR200_19.6-year Graduation rate - bachelor's degree within 150% of normal time \
0 41
1 53
2 54
3 66
4 43
5 56
6 66
7 42
8 69
9 47
10 51
11 48
12 64
13 53
14 60
15 59
GR200_19.8-year Graduation rate - bachelor's degree within 200% of normal time
0 47
1 60
2 62
3 69
4 49
5 63
6 72
7 49
8 75
9 56
10 57
11 58
12 68
13 58
14 62
15 63 >
In [10]:
colName_2009=GR2009_df.columns[4]colName_2009
Out[10]:
"GR200_09_RV.6-year Graduation rate - bachelor's degree within 150% of normal time"
In [11]:
colName_2019=GR2019_df.columns[4]colName_2019
Out[11]:
"GR200_19.6-year Graduation rate - bachelor's degree within 150% of normal time"
0 California State University-Bakersfield
1 California State University-Stanislaus
2 California State University-San Bernardino
3 California State University-Chico
4 California State University-Dominguez Hills
5 California State University-Fresno
6 California State University-Fullerton
7 California State University-East Bay
8 California State University-Long Beach
9 California State University-Los Angeles
10 California State University-Northridge
11 California State University-Sacramento
12 California State University Maritime Academy
13 California State University-San Marcos
14 California State University-Monterey Bay
15 California State University-Channel Islands
Name: institution name, dtype: object
xLims=np.array([20,75])yLims=xLimsfig,ax=plt.subplots(nrows=1,ncols=1)fig.set_size_inches(9,9)ax.plot([xLims[0],xLims[1]],[yLims[0],yLims[1]],'--',color='gray',alpha=0.5)ax.scatter(GR2009_df[colName_2009],GR2019_df[colName_2019],marker='.')fori,txtinenumerate(GR2009_df["coded names"]):ax.annotate(txt,(GR2009_df[colName_2009][i],GR2019_df[colName_2019][i]),size=15)ax.set_aspect(1)ax.set_xlabel('2009 Graduation rate (%)',size=17)ax.set_xlim(xLims)ax.set_ylabel('2019 Graduation rate (%)',size=17)ax.set_ylim(yLims)ax.set_title("CSU Graduation Rates by Campus over 10-year span (2009, 2019)\nBachelor\'s Degree within 150% of normal time\n",size=20)
Out[71]:
Text(0.5, 1.0, "CSU Graduation Rates by Campus over 10-year span (2009, 2019)\nBachelor's Degree within 150% of normal time\n")
fig2,ax2=plt.subplots(nrows=1,ncols=2)fig2.set_size_inches(11,5)#ax2[0].hist(grRatios)nps.histPlotter(10,grRatios,axes=ax2[0])ax2[0].set_xlabel('rate ratio',size=17)ax2[0].set_ylabel('count',size=17)ax2[0].set_title('Distrib. of Grad. Rate Ratios',size=20)nps.qqPlotter_normal(grRatios,10,axes=ax2[1])ax2[1].set_xlabel('data quantiles',size=17)ax2[1].set_ylabel('theoretical normal quantiles',size=17)ax2[1].set_title('Q-Q comparison plot',size=20)
Out[80]:
Text(0.5, 1.0, 'Q-Q comparison plot')
From the plots above, we are not convinced that graduation rate ratios are normally-distributed. To determine statistical significance of the observed increase in recent rates, the best approach might be to employ a non-parametric bootstrap of studentized hypothesis test or confidence limits.
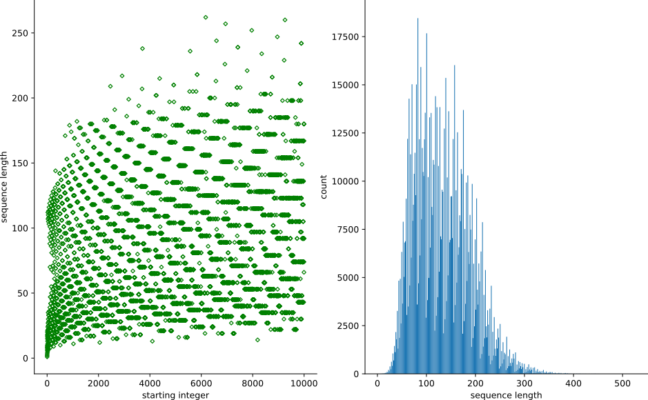
I came across the following example challenge from Project Euler on freeCodeCamp‘s website and it seemed that Collatz sequence generation in Python would prove to be a worthy test of our programming meddle.
Instructions are as follows:
The following iterative sequence is defined for the positive set of integers:
$n \rightarrow n/2$, if $n$ is even,
$n \rightarrow 3n + 1$, if $n$ is odd
Using the rule above and starting with 13, we generate the following sequence:
It can be seen that this sequence (starting at 13 and finishing at 1) contains 10 terms. Although it has not been proved yet (Collatz problem), it is thought that all starting numbers finish at 1.
Which starting number, under one million, produces the longest chain?
Generating the Collatz sequence: a first stab
Owing to how they are defined, Collatz sequences can be generated by a recursive algorithm comprised of only a few simple, thoughtfully placed, operations. Let’s see if we can do that here:
In [1]:
# Collatz conjecture Project Euler example defcollatz(seq):# seq must be an integer greater than 0 or# a list of intergers all of which are # greater than 0iftype(seq)==int:seq=[seq]# insert int arg into listifseq[-1]==1:# recursion termination pathpass# exit clause if last # element is 1else:# build sequence via recursionifseq[-1]%2 == 0: # if last element is even
seq.append(int(seq[-1]/2))# divide by 2collatz(seq)# and append result, self-call# with updated list as arg.else:# alternatively, if last element is oddseq.append(int(3*seq[-1]+1))# mult. by 3collatz(seq)# and add 1, append result,# self-call with updated list# as arg.returnseq# set output to be entire list collatz(13)
Out[1]:
[13, 40, 20, 10, 5, 16, 8, 4, 2, 1]
Yep, it works.
But truth be told, I’m less than thrilled with the type-conversion and list-append operations. How about we try to work out something a bit more elegant.
A more refined Collatz sequence generator
Instead of using a list, we can unpack a tuple of the sequence in the function’s argument definition. This permits us to insert each new sequence entry by including it as the last argument in a recursive self-call. Employing this approach, we eliminate the separate list-append operation that we were forced to use in the previous version. But just as before, the sequence grows by one more element with each recursive step until self-calls are by-passed when the last entry equals 1.
In [2]:
# A more elegant Collatz constructordefcollatz2(*seq):# seq must be an integer greater than 0 or# a sequence of intergers all of which are # greater than 0ifseq[-1]==1:# terminate recursion if pass# last element is 1else:# build sequence via recursionifseq[-1]%2 == 0: # case: last element even
# include n/2 result as last argument# of self callseq=collatz2(*seq,int(seq[-1]/2))else:# case: last element odd# include 3n+1 result as last argument# of self callseq=collatz2(*seq,int(3*seq[-1]+1))returnseq# set output to be entire sequence.
Reproduce example sequence
Alright, now that we’ve defined our refined Collatz generator, let’s verify that it reproduces the sequence given in the instructions above.
In [3]:
collatz2(13)
Out[3]:
(13, 40, 20, 10, 5, 16, 8, 4, 2, 1)
Goody gumdrops; it does.
Let’s try another starting integer, say, after switching digit position. This time, for the sake of brevity, let’s just examine some meta properties of the generated sequence.
In [4]:
collatzList=collatz2(31)print('Number of elements in sequence: {}'.format(len(collatzList)))print('Last number in sequence (should be 1): {}'.format(collatzList[-1]))print('Finally, how about the largest number in the sequence: {}'.format(max(collatzList)))
Number of elements in sequence: 107
Last number in sequence (should be 1): 1
Finally, how about the largest number in the sequence: 9232
Yowza!
In this case, the Collatz sequence contains a number that is two orders of magnitude larger than the number we started with! We would do well to remember this as we move forward.
Onto the challenge…
Testing the waters
Before unleashing this beast on integers approaching one million, let’s first find out the maximum size integer that our machine and Python can handle.
In [5]:
importsysprint('Maxiumum integer that can be processed by our machine: {:.5E}'.format(sys.maxsize+1))
Maxiumum integer that can be processed by our machine: 9.22337E+18
Yeah our maximum-allowable integer seems to be pretty-darn-large despite our admittedly lack-lustre setup. Note, however, that integers in a Collatz sequence can be orders of magnitude larger than the starting number. Recall the sequence for integer 31 above; it had an integer >9000 in its sequence. Even so, ~9E18 should be large enough (famous last words…) for a sequence that starts around 1e6–hopefully 12 orders of magnitude is sufficient space for intermediate values of the sequence to grow as need be. Let’s at least keep our fingers crossed, though, when we call our generator with arguments valued in this neighborhood.
In [6]:
importtimeforiinrange(-1,2):start=time.time()collatzList=collatz2(1e6+i)duration=time.time()-startprint('It took {:.5} seconds to generate the Collatz sequence for {}.'.format(duration,int(1e6+i)))print('The sequence contains {} elements'.format(len(collatzList)))
It took 0.0025585 seconds to generate the Collatz sequence for 999999.
The sequence contains 259 elements
It took 0.00027061 seconds to generate the Collatz sequence for 1000000.
The sequence contains 153 elements
It took 0.00016356 seconds to generate the Collatz sequence for 1000001.
The sequence contains 114 elements
No sweat.
No fan revving up, and no never-ceasing cyclic processing indicators to speak of; definitely a good sign.
A processing time on the order of 1 millsecond per high-valued integer should not be prohibitive, in terms of time, for a brute force search to find the number with the longest Collatz sequence in domain [1, 1E6). (There’s that “should” again.)
Based on these measurements, and using a convenient figure between extremes, one million numbers, that each take around, say, 1 millisecond to process, would mean a total duration of about 1e3 seconds (less than 17 minutes).
Again, this is a very loose figure to estimate the overall time to compute all Collatz sequences over the entire domain. Please remember that we expect that for some integers processing will take much longer than 1 millisecond, and for others, their Collatz sequences can be computed much faster, as we see above. My guess: 17 minutes is likely an overestimate considering that we timed numbers at the high end of the domain.
Now let’s compare our estimate to actual.
Iterate over domain and record sequence lengths
In [7]:
# Which number under 1E6 produces the longest chain?# Brute force search??? It could take a while...start=time.time()collatzList=[[len(collatz2(n)),n]forninrange(1,int(1e6))]duration=time.time()-startprint('It took {:.5} seconds to generate the Collatz sequences over [1,1e6).'.format(duration))
It took 212.82 seconds to generate the Collatz sequences over [1,1e6).
Woops. For those of you who’d prefer a processing time in human-interpretable units: 213 seconds is about 3.5 minutes.
Not all that bad of a wait considering our estimate of 17 minutes above.
Find longest sequence and its starting integer
All that is left to do now is select the longest tuple and corresponding starting integer.
In [8]:
longest=max(collatzList)print('The longest Collatz sequence is comprised of {} elements for number {}'.format(longest[0],longest[1]))
The longest Collatz sequence is comprised of 525 elements for number 837799
And there you have it.
Just for kicks: plot stop times
While we’re here, and have at our fingertips a large array of Collatz sequence lengths, how about we make ourselves a nifty banner graphic for his post?
Below, we generate a scatter plot of Collatz stop times (sequence lengths) for integers in the domain [1, 1e4].
Notice the widening, curved striations in the left plot, as well as oscillating bin heights in the histogram on the right. To me, this apparent structure indicates some underlying pattern pulling strings behind the progression of Collatz sequences. Well, as inviting as it may be to find one, no one has yet. The Collatz Conjecture remains unproven.
Last time, in part two, we built and tested our set container class, ModSet(), with a variety of methods that will prove useful when we construct the power set. Methods included copying, nesting/unnesting, filtering to keep only unique members as well as set-union and set-subtraction operations. You will see that most of these will be used, either implicitly or explicitly, in both Binary Mask and Recursive methods of generating power sets.
Preliminaries
Our ModSet() class definition is a must (obviously); let’s run its script so it will be ready and waiting for us when it comes time to make an instance. You can download the script from github here: modset.py
In [1]:
%run modset.py
When we are ready to build our power set, we’ll measure the time it takes each of the two routines to complete, so we can compare their performance. As a preliminary, let’s import the time module so it stands at ready.
In [2]:
importtime
Of course we will need an example source set to operate on. Let’s define it now and be done with it.
In [3]:
clumsyPrez=ModSet(set([6.1,2021,"fight like hell","we love you",('impeachment','#2')]))
Binary Mask power set generator
In this iterative-based approach, we will populate the power set by applying binary masks to extract out member subsets, one-by-one, from the source set in ModSet().val. If you recall, a verbal description of power set generation using a binary mask we discussed way back in part one; you can find it here. Below, we first provide an overview of our binary mask power set generator routine, followed by the routine itself, with heavy commenting, concluded with a detailed walk-through after that.
Overview
The method, named .powerSet_bin(), contains 19 lines and calls .pushDown() and .union() sibling methods. Though we could use NumPy here to make mask generation and member extraction more compact, we did not want to confound the comparison (to our recursive approach to follow) by incorporating functionality of an external module. Already, the code has been somewhat compressed by use of generator expressions.
Flow of control
The routine below can be divided into two main blocks: variable initialization, and the run-time loop that builds each binary mask for extracting the corresponding subset on each iteration. The loop populates the power set member-by-member and terminates when all $2^n$ members have been added. Because indexing is crucial in this approach, you’ll notice heavy use of range() and list() data-types. As you’ll see later, our recursive approach requires no such crutch.
In [ ]:
classModSet():...# Generate powerset via direct, binary mask approachdefpowerSet_bin(self):## Initialize local variables ##S=list(self.val)# convert to list for indexingsetSize=len(self.val)# count number of members in source setpsetSize=pow(2,setSize)# calculate the number of elements in the power setlastIndex=setSize-1# index value of last membersetIndices=range(0,setSize)# make indices list for source setpsetIndices=range(0,psetSize)# make indices list for power set to be builtbMasks=[[FalseforsinsetIndices]forpinpsetIndices]# Initialize binary mask pSet=ModSet(set())# initialize power set as empty ModSet() instancepSet.pushDown(1)# and nest it down one level for later joining## Populate powerset with each subset, one at a time ##foriinpsetIndices:# loop through each member of power set## Generate binary mask for subset i of power set ##val=i# assign current pSet index as current "value" of mask forjinsetIndices:# loop through each bit-digit of maskif(val>=pow(2,lastIndex-j)):# if mask value >= value of current bit,bMasks[i][lastIndex-j]=True# then set corresp. mask bit to "true"val-=pow(2,lastIndex-j)# subtract value of current bit from# mask value to determine next bit-digit## Form subset i of power set ### Use generator expression for compactnessdummySet=ModSet(set([S[k]forkinsetIndicesifbMasks[i][k]==True]))dummySet.pushDown(1)# nest ModSet instance down one level for union joinpSet.union(dummySet)# include new subset in power setreturnpSet,bMasks# return complete power set and binary masks as output
Aside: initializing the mask
To have each and every element alterable in our list of binary masks, bMasks, we need to individually assign each and every element within the nested list. If you attempt to initialize bMasks like this, bMasks = [[False]*len(setIndices)]*len(psetIndices)], (as we did on our first attempt!), you will find that you cannot change individual elements of bMasks later on. That is
changes to Trueall row-entries in the second column, rather than just the fourth, since all point to the same instance of True. However, if you initialize bMasks using a list completion, the nested list assembles with a hash to a unique instance for each and every element therein
so that we can make the individual bit flips necessary for our routine. Our apologies for the digression; we felt the need to address this “rookie” Python mistake for those who may be unaccustomed to using list objects in this, possibly unusual, manner.
Testing the binary mask routine
With the binary mask routine complete, we’re ready to build our power set. Below we’ve sandwiched the call within two time.time() reads, so we can measure its runtime duration. Let’s examine bMasks output first.
In [6]:
tStart=time.time()# clock start timestamppSet_bin,bMasks=clumsyPrez.powerSet_bin()# call our binary mask power set generatorduration=time.time()-tStart# calc run duration by subtracting tStart from current time.bMasks# show list of binary masks
Above, you can see that masks progress from all False to all True in a logical pattern. This ordering would be a great feature if we cared about how members are ordered in our power set. But sets, strictly defined, are not distinguished by the ordering of their members (Van Dalen, Doets, De Swart; 2014). That is, set $\{a, b, c\}$ is equivalent to set $\{c, a, b\}$ and $\{b, a, c\}$, and so on.
So, after taking a look at our power set in pSet_bin, we see that the nice ordering was all for naught.
In [7]:
# Report duration of binary mask power set generationprint('The Binary Mask approach took %0.6f seconds to complete.'%(duration))print('The power set contains %i subset elements'%(len(pSet_bin.val)))pSet_bin.val# show power set output; remember, this is a set!
The Binary Mask approach took 0.007774 seconds to complete.
The power set contains 32 subset elements
Out[7]:
{set(),
{'fight like hell', 'we love you'},
{'fight like hell', ('impeachment', '#2'), 6.1, 'we love you'},
{'fight like hell', 2021, 6.1, 'we love you'},
{'fight like hell', 6.1, 'we love you'},
{'fight like hell'},
{'we love you'},
{('impeachment', '#2'), 'fight like hell', 'we love you'},
{('impeachment', '#2'), 'fight like hell'},
{('impeachment', '#2'), 'we love you'},
{('impeachment', '#2'), 2021, 'fight like hell', 'we love you'},
{('impeachment', '#2'), 2021, 'fight like hell'},
{('impeachment', '#2'), 2021, 'we love you'},
{('impeachment', '#2'), 2021, 6.1, 'fight like hell'},
{('impeachment', '#2'), 2021, 6.1, 'we love you'},
{('impeachment', '#2'), 2021, 6.1},
{('impeachment', '#2'), 2021},
{('impeachment', '#2'), 6.1, 'fight like hell'},
{('impeachment', '#2'), 6.1, 'we love you'},
{('impeachment', '#2'), 6.1},
{('impeachment', '#2')},
{2021, 'fight like hell', 'we love you'},
{2021, 'fight like hell'},
{2021, 'we love you'},
{2021, 6.1, 'fight like hell', 'we love you', ('impeachment', '#2')},
{2021, 6.1, 'fight like hell'},
{2021, 6.1, 'we love you'},
{2021, 6.1},
{2021},
{6.1, 'fight like hell'},
{6.1, 'we love you'},
{6.1}}
From the power set output string above, it looks like we have many sub-set instances as members of one big super-set. But, if you recall from all the way back in part one, this is not the case; our power set pSet_bin is actually a ModSet() object, whose .val attribute is a set, each element of which is another ModSet() instance that contains one unique sub-set of the original source set (as its .val attribute). We defined the ModSet.__repr__() method to return the code representation of its .val attribute; that’s the reason why the return string from calling pSet_bin.val appears in this set-resembling format.
Recursive power set generator
In part one, we went over a recursive algorithm that we used to design our recursive power set generator below. You can find it here if you would like a refresher.
Overview
Our recursion-based method for generating power sets contains just 11 lines of code but requires five sibling methods, as well as itself, to run. Though .powerSet_rec() has fewer lines than .powerSet_bin(), it relies more heavily upon behavior of sibling methods in the ModSet() class, i.e. .__copy__(), .pushDown(), .diffFunc(), .union() and .removeDuplicates() to perform the respective obligatory processing tasks of duplication, nesting, extraction, joining and filtering. Unlike the Binary Mask approach above, indexing is not needed here, and hence, not employed. Through recursion, we can generate the identical power set using thoughtfully-placed set-subtraction, -union and -filtering operations.
In [ ]:
classModSet():...# Generate power set recursively.defpowerSet_rec(self):pSet=self.__copy__()# Preserve self instance; its copy, pSet# will be alteredpSet.pushDown(1)# Nest pSet for later joining.iflen(self.val)>0:# Recursion termination conditionforelSetinself.val:# Iterate through members of set self.val# Generate subset that remains after removing current# element, elSet, from set self.valdummySet=self.diffFunc(ModSet(set([elSet])))# To current powerset, append the powerset of the# subset from previous steppSet.union(dummySet.powerSet_rec())# Self-call power set method,# union join power set of # dummySet with pSetreturnpSet# Return power set at current # level of recursionelse:dummySet=ModSet(set())# Generate instance of ModSet of empty setdummySet.pushDown(1)# Nest empty set down one level so it canreturndummySet# be union-joined in the recursion level# above (that called this current run).
Flow of control
First a duplicate of the calling instance is made to serve as the (local) power set within our routine. This instance is promptly pushed down one level so it can be joined by union later, if necessary. Next, the number of elements in the calling instance are counted. If empty, an empty ModSet() instance is returned on exit of the routine. This case path is the exit condition for the recursive flow; eventually all calling instances will dwindle down to empty as members are stripped from them in the alternative, non-empty, case that we’ll describe next.
If the calling instance is not empty, .powerSet_rec() iterates over the elements therein, each time subtracting out the current element, elSet, and calling itself again to build the power set from elements that remain. Output from this recursive call is then joined by union with pSet. Remember that every time pSet.union() runs, it calls the filtering method removeDuplicates() to retain only unique members in pSet as it is assembled.
When the loop completes, and all subsets have been included at the present level, the local instance of pSet is returned so that it can be union-joined with the pSet instance inside the calling-function one level above. The method continues in this fashion until pSet at the top-most level of recursion is fully populated, at which point output is returned in response to the initial method call.
[Phew..!]
Let’s give it a whirl and gauge its run-time duration.
Testing the recursive routine
In [8]:
tStart=time.time()pSet_rec=clumsyPrez.powerSet_rec()duration=time.time()-tStartprint('The Recursive approach took %0.6f seconds to complete.'%(duration))print('The power set contains %i subset elements'%(len(pSet_rec.val)))pSet_rec.val
The Recursive approach took 0.013909 seconds to complete.
The power set contains 32 subset elements
Out[8]:
{set(),
{'fight like hell', 'we love you'},
{'fight like hell', ('impeachment', '#2'), 6.1, 'we love you'},
{'fight like hell', 2021, 6.1, 'we love you'},
{'fight like hell'},
{'we love you', ('impeachment', '#2'), 'fight like hell'},
{'we love you', 2021, 'fight like hell'},
{'we love you', 6.1, 'fight like hell'},
{'we love you'},
{('impeachment', '#2'), 'fight like hell'},
{('impeachment', '#2'), 'we love you'},
{('impeachment', '#2'), 2021, 'fight like hell', 'we love you'},
{('impeachment', '#2'), 2021, 'fight like hell'},
{('impeachment', '#2'), 2021, 'we love you'},
{('impeachment', '#2'), 2021, 6.1, 'fight like hell'},
{('impeachment', '#2'), 2021, 6.1, 'we love you'},
{('impeachment', '#2'), 2021, 6.1},
{('impeachment', '#2'), 2021},
{('impeachment', '#2'), 6.1, 'fight like hell'},
{('impeachment', '#2'), 6.1, 'we love you'},
{('impeachment', '#2'), 6.1},
{('impeachment', '#2')},
{2021, 'fight like hell'},
{2021, 'we love you'},
{2021, 6.1, 'fight like hell'},
{2021, 6.1, 'we love you', 'fight like hell', ('impeachment', '#2')},
{2021, 6.1, 'we love you'},
{2021, 6.1},
{2021},
{6.1, 'fight like hell'},
{6.1, 'we love you'},
{6.1}}
As promised, we see the same power set as we saw from the Binary Mask approach. But unlike that approach, there is no mask output for us to examine this time.
Quick-and-dirty efficiency comparison
For a given programming objective, recursive algorithms tend to be less efficient than their iterative equivalents when used in imperative-based languages, like Python, where iteration is preferred (Recursion (computer science), Wikipedia). Below we hobbled together a quick script to measure, and statistically compare, processing times of the two methods of power set generation of clumsyPrez. We instruct the two power set generators to each run 500 times in a randomly alternating sequence to destroy potential processing-related biases (e.g. sequential, timing) that could otherwise arise by running the two in separate blocks.
In [9]:
importnumpyasnpimportmatplotlib.pyplotasplt# routine to repeatedly collect run-time durations# of functions genFunc1 and genFunc2defgenDurationsDist(genFunc1,genFunc2,nReps):durations=np.zeros(2*nReps)# initialize output arraygenFuncs=[genFunc1,genFunc2]# make list of the two functions to run# initialize an array to contain the run-sequence of the two functionsfuncSeq=np.concatenate([np.zeros(nReps),np.ones(nReps)]).astype(int)np.random.shuffle(funcSeq)# shuffle the ordering of the sequenceforiinnp.arange(0,funcSeq.shape[0]):# iterate over random sequencetStart=time.time()# start timestampgenFuncs[funcSeq[i]]()# run one of the two functions based on funcSeqdurations[i]=time.time()-tStart# end timestamp, calc duration# separate and return the two sets of durationsreturndurations[funcSeq==0],durations[funcSeq==1]durations_bin,durations_rec=genDurationsDist(clumsyPrez.powerSet_bin,clumsyPrez.powerSet_rec,500)
Now that we have distributions of processing times from the two power set generators, we can plot histograms and Q-Q plots to get an idea of their locations and shapes.
In [10]:
importnonparametric_statsasnpsplt.rcParams['figure.figsize']=[7,5]durs=(10**3)*np.array([durations_bin,durations_rec])# Obtain color cycle that matplotlib usesprop_cycle=plt.rcParams['axes.prop_cycle']colors=prop_cycle.by_key()['color']# plot histograms of duration distributionslabels=['Bin. Mask','Recursive']ax=nps.histPlotter(50,*durs,labels=labels,colors=colors)ax.set_title('Runtime durations of 2 power set generators')ax.set_xlabel('duration (msec.)')ax.set_ylabel('counts')ax.legend()# Examine Q-Q plots to compare distributions to# their corresponding theoretical normal distsfig,axs=plt.subplots(nrows=1,ncols=2)fig.tight_layout()foriinrange(0,2):nps.qqPlotter_normal(durs[i],30,axes=axs[i],color=colors[i])axs[i].set_title(labels[i]+' gen. Q-Q')axs[i].set_xlabel('theoretical normal')ifi==0:axs[i].set_ylabel('data')
The two distributions certainly do not appear to be normally distributed; they depart from Normal theoretical very early on. Consequently the typical two-tailed Student t-test cannot be used here. Below, we import and run the Mann-Whitney non-parametric comparison test to assess if the difference between the two reaches statistical significance.
In [11]:
fromscipy.statsimportmannwhitneyuasmwumed_bin=(10**3)*np.median(durations_bin)# compute median duration of Bin. Mask ps durationsmed_rec=(10**3)*np.median(durations_rec)# compute median duration of Recursive ps durationsprint('Median Bin. Mask duration: %0.2f msec., Median Recursive duration: %0.2f msec.'\
%(med_bin,med_rec))# Run non-parametric test to determine if differences between # distributions are statistically significantuStat,pVal=mwu(durations_bin,durations_rec)print('Mann-Whitney U statistic: %0.2f, p-value: %0.2e'%(uStat,pVal))
Median Bin. Mask duration: 2.11 msec., Median Recursive duration: 4.59 msec.
Mann-Whitney U statistic: 487.00, p-value: 5.41e-164
Measuring the time elapsed for each of the two approaches, we find that, on average, our recursive algorithm does indeed take about twice the time to complete on our machine as the binary-mask method (4.59 ms versus 2.11 ms, U = 487, p < 0.01). Of course, ours is certainly not a very controlled comparison; so please take the result with “a grain of salt” if you will.
Summary
In part one we discussed power sets and their relation to the binary theorem. In addition, we mapped out a recursive procedure for generating the power set. A brief investigation revealed that Python’s set() class could not accommodate our need to include subsets within a set as in the case of power sets. To solve the problem, we introduced a custom container class with a set-valued attribute, whose instances are “hashable” and thus, eligible for membership in set objects.
Starting with the container strategy from part one, in part two we expanded our custom class, ModSet(), to include methods that perform copying, nesting, uniqueness-filtering, set-union and set-difference operations as well as others. We verified that all ModSet() methods functioned as desired. Many of the methods added would prove necessary for both methods of power set generation to follow.
In part three, we realized our goal of generating power sets. First, we detailed program flow of both the Binary Mask and Recursive approaches of power set generation. The mask routine used list indexing and took more lines of code than recursive method, but called fewer class methods. Our Recursive approach was shorter in terms of lines of code because it incorporated more sibling methods of the ModSet() class. We then explained the control flow of the recursive generator hoping to illustrate how recursive algorithms function. Finally, we compared relative run times of the two approaches. It turned out that, as expected, the Binary Mask routine took less time to run than its recursive counterpart.
Lastly, stay tuned for part foura where we’ll walk-through and test a more efficient algorithm for generating power sets in the ModSet() class.
In part one, we showed that instances classes are hashable, so they can be included as elements of a set object. If the class instance happens to have a set-valued attribute, we effectively have a set with another set as a member, made possible by the instance acting as a “container” (Bernstein, M). In the post that follows, we’ll craft a new class that incorporates the container behavior illustrated in part one, as well as a number of other methods that will prove necessary when we build power sets in part three.
Define a set container class
Using the illustrative example in part one, we will define a new class, ModSet(), with the same constructor and representation methods. New instances of the class will require a set argument, either occupied or empty. In addition, we will define methods to copy, nest and unnest instances of the class.
In [ ]:
classModSet():# Instance constructordef__init__(self,setElement):self.val=setElement# set arg saved in .val attribute# String eval representation of self instance def__repr__(self):returnself.val.__repr__()# Return string eval represent.# of string object in .val# Method to make a copy of self instancedef__copy__(self):returnModSet(self.val)# Modify .val to contain the set of itself, of itself, ...# nesting .val "depth" number of levels.defpushDown(self,depth):whiledepth>0:self.val=set([ModSet(self.val)])depth-=1# Remove one nesting level from set in self.val.# If un-nested, ignore.defpullUpOneLevel(self):listSet=list(self.val)iflen(listSet)==1:self.val=listSet[0].valelse:pass# Remove height number of nesting levels from set in# self.val by repeatedly calling above methoddefpullUp(self,height):whileheight>0:self.pullUpOneLevel()height-=1
Testing these, let’s define a set of mixed immutables and nest it three levels deep.
Just like Python’s set class, we will make sure that each member of ModSet be unique according to the value of its .val attribute. When a ModSet is comprised of immutables, the set() class enforces uniqueness for us automatically. However, if a ModSet contains other ModSets, we require an additional method to enforce uniqueness among them as well.
In [ ]:
classModSet():...defremoveDuplicates(self):uniqueSet=set()# initialize as empty the unique set to be builtforsinself.val:# s is a member of the ModSet().val setinUniqueSet=False# initialize match detection flag as falsesTest=s# default conditional testing value for sforusinuniqueSet:# us is a member of the uniqueSet setusTest=us# default conditional testing value for usifisinstance(us,ModSet):# if member us is a ModSetusTest=us.val# change testing value to its attributeifisinstance(s,ModSet):# if member s is a ModSetsTest=s.val# change testing value to its attributeifusTest==sTest:# compare us and s testing values on this runinUniqueSet=True# if match, set existence flag to trueifnotinUniqueSet:# only add member s to uniqueSet ifuniqueSet.add(s)# match is NOT detectedself.val=uniqueSet# set .val to the uniqueSet from above
Testing the uniqness enforcement method
After we added removeDuplicates() to our class definition, we can test it as follows.
In [5]:
prez1=ModSet(set([('televised','summit'),'DMZ',12.6,2019,'\"bromance\"']))# inst. 1prez2=ModSet(set([('televised','summit'),'DMZ',12.6,2019,'\"bromance\"']))# inst. 2prez3=ModSet(set([('televised','summit'),'DMZ',12.6,2019,'\"bromance\"']))# inst. 3print(set([id(prez1),id(prez2),id(prez3)]))# each instance held in its own memory blockmodSetOfPrez=ModSet(set([prez1,prez2,prez3]))# define a ModSet of ModSet instancesprint(modSetOfPrez.val)# set class sees each instance as unique though they contain # equivalent values in their attributes
For the power set routines to come, we need instances of ModSet() to join by union and also separate by set-subtraction. Below, we define methods for these operations as well as set-intersection.
In [ ]:
classModSet():...# union-join multiple items, enforce that ModSet members be uniquedefunion(self,*modSets):formodSetinmodSets:self.val=self.val.union(modSet.val)# this is union method from set classself.removeDuplicates()# removes duplicate-valued instances of ModSet members# take set intersection of multiple itemsdefintersection(self,*modSets):formodSetinmodSets:self.val=self.val.intersection(modSet.val)# method from set class# take set difference of multiple items. Note: arg order matters here! defdifference(self,*modSets):formodSetinmodSets:self.val=self.val.difference(modSet.val)# method from set class# version of above method that returns a new instance for assignment.# Note: only two arguments here.defdiffFunc(modSet1,modSet2):returnModSet(set.difference(modSet1.val,modSet2.val))
Testing ModSet union
With the set operation methods now included in the class, let’s test union-joining of non-ModSet objects.
The three separate ModSets have been merged into a single ModSet, charges. Notice that string member 'of' appears only once, as it should, though it is present in charge1, charge2, and charge3. Now, we’ll test union operation with ModSet members present as well.
First, we’ll nest down by one level each of the three charges, so that we can test ModSet.union(). This time we’re interested in the case when ModSet-of-ModSets are present in the pool of objects to be joined. By “ModSet-of-ModSet”, we mean a ModSet instance that has another ModSet instance as a member of its set-valued .val attribute–the result of ModSet.pushDown(1). During the union call, these ModSet-of-ModSet objects will be routed through paths of .removeDuplicates() that we’ve set up specifically for them.
You should notice that though we have included charge1 twice in the method-call, its value, {'Congress', 'obstruction', 'of'}, appears just once in the output. So, we may conclude that the .removeDuplicates() method does correctly enforce uniqueness among ModSet-of-ModSet members. Members of {'all', 'fake', 'news'} have been included as well. Now that we’ve shown that .union() works as expected, we can move on to test .intersection().
Testing ModSet intersection
In [9]:
claim1=ModSet(set(['rounding','the','bend']))# define a new instance of ModSetclaim2=ModSet(set(['dems','stole','the','election']))# define another new instanceclaim1.union(charge1,charge2)# union-join charges 1 and 2 from above with claim1 claim2.union(charge2,charge3)# union-join charges 2 and 3 from above with claim2claim1.intersection(claim2)# perform set-intersection of claims 1 and 2claim1# output the post-intersection result
Out[9]:
{{'power', 'of', 'abuse'}, 'the'}
Above we form two “mixed” ModSet() instances that contain both top-level strings as well as sub-ModSets as members. We can see, after joining the two by set intersection, the result is what we expect: only 'the' remains from the strings and only charge2 survives among the ModSets.
Testing ModSet set-difference
Above we included two methods for performing set-subtraction within the ModSet() class. The first, called .difference(), is an inline function that modifies the original instance from which it is called. Removing charge2 from charges
leaves charges with all but the {'abuse', 'of', 'power'} member in the result. So, check.
The second method, that we’ve named .diffFunc(), is a functional version of set-subtraction that returns the result as a new instance ModSet() leaving its originating instances unchanged. To test .diffFunc(), we’ll now attempt to remove charge1 from charges (since charge2 has already been removed in the previous step).
You can see that the value from charge1, {'obstruction', 'of', 'Congress'}, is absent from chargesReduced, though all others from its parent, charges, are present.
Lastly, let’s examine charges to make sure that this particular instance has not been modified since last step.
And there the charge remains, in all its glory, one could say…
Though our testing of ModSet() above has been far from exhaustive, we hope you are convinced that instances of it will behave as we intend them to. At this point, we can finally move on to our main objective: building power sets. We’ll do this in part three to come.
The above code comprises the core of our ModSet() class. We’ll walk-through the power set generating methods in part three. You can download ModSet()‘s complete definition from github: modset.py
In this three part series, we will demonstrate how to construct the power set using both iterative and recursive algorithms. You may recall, the power set of a set $S$ is the collection of all (unique) subsets of $S$, including the empty set and $S$ itself. Though Python's set class does not accept its own set objects as members, we will define a new object class, ModSet(), that encapsulates member subsets in hashable containers so that they can be included within set instance, the power set.
Here in part one, we'll use a minimal working example to demonstrate our solution to the subset inclusion problem. Next, in part two, we construct the ModSet() object with all the methods necessary to support power set generation by two distinct approaches. Finally, in part three we develop and run binary mask and recursive routines for generating power sets in Python.
Now, a bit about power sets.
Power sets defined and how to build them
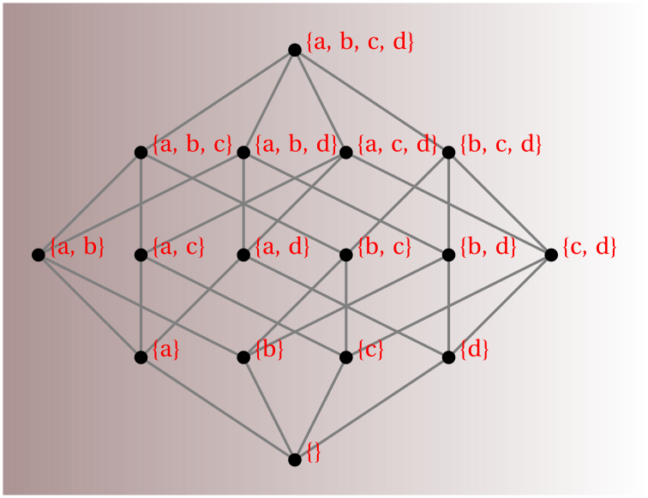
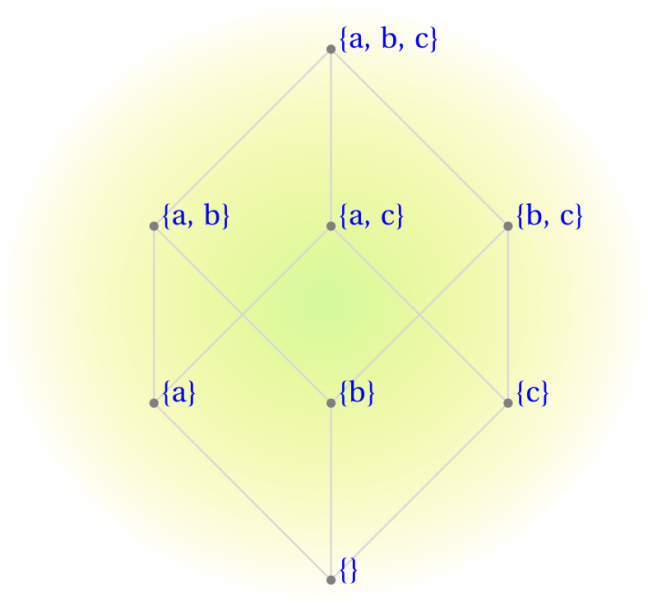
If a set $S$ has $n$ elements, its power set will have $2^n$ member subsets; these include the complete "source" set, $S$ itself, as well as the empty set, $\emptyset$. For example, the power set of set $\{x,y,z\}$ is: $\{\emptyset, \{x\}, \{y\}, \{z\}, \{x, y\}, \{x, z\}, \{y, z\}, \{x, y, z\}\}$. Please notice that there are $2^3=8$ subset elements, all of which are unique; that is, no two subsets contain the same collection of members.
Why $2^n$? Because all possible subsets can be formed by selecting their members according to digit occurrence in the base-2 integers that count from $0$ to $2^n$
Clear as mud, right? Don't worry, we'll explain.
The Binary Mask approach
Say we have a source set comprised of four members, $\{a,b,c,d\}$. The corresponding mask will have four digits that can each take on values of either $0$ or $1$. If a mask digit equals $1$ we keep the element in the corresponding location of the source set, if a digit is $0$, we reject the corresponding element.
Working with binary masks
Here's an illustrative example: binary mask $0101$ operating on source set $\{a,b,c,d\}$ would form subset member $\{b,d\}$ of the power set. Similarly, binary mask $1110$ selects subset $\{a,b,c\}$. Using the same rule, mask $0000$ selects $\emptyset$, while $1111$ forms the original source set of all four elements. There are $2^4=16$ unique bit combinations in a 4-digit binary mask, so there are $16$ unique member subsets in the power set of a four-element source set. Now, extending this procedure to a set comprised of $n$ elements rather than $4$, you can see that its power set will have $2^n$ member subsets by the same rule (the binomal theorem).
The above procedure may seem to have a certain efficiency and elegance in its directness; in this series, we'll call this method "the Binary Mask approach".
But there is another procedure we can use to build power sets...
A Recursive approach
Alternatively, you can take your source set, $\{a,b,c,d\}$, remove one of its members, $a$, then define a new subset with the members that remain, $\{b,c,d\}$, and include it as a new element in a collection. We apply the same element removal procedure to the resultant subset from the previous step, then to the result of the current step, and to the result of the next step, and so on, until we are left with a result that is empty. If we repeat the removal operation for all members of the starting set and each resultant subset, you will produce the a collection of subsets that includes the power set, with many redundant subsets in the collection as well. We'll address this issue of duplication in the next section.
Recursion walk-through
For example: removing $b$ from our source set leaves subset $\{a,c,d\}$. Removing element $c$ from subset $\{a,c,d\}$ leaves subset $\{a,d\}$. Taking $a$ from subset $\{a,d\}$ results in subset $\{d\}$. And finally, removing element $d$ from subset $\{d\}$ produces the $\emptyset$. Then we go all the way back up to the top, this time taking $c$ from $\{a,b,c,d\}$ and repeat the entire stripping procedure until we are left with $\emptyset$ as above. Next we do the same starting with members $d$ and $a$; repeating the full stripping procedure for each.
Notice that we could have removed any existing member from any set or subset at any step in the process--not only the particular members stated above. For example we could have removed $d$ from subset $\{a,c,d\}$ instead of $c$ at that step. If we explore every possible sequence of element removal, we'll notice that identical subsets can be produced by different sequences (e.g. $\{a,c\}$ results from sequence $\{a,b,c,d\} \rightarrow \{a,b,c\} \rightarrow \{a,c\}$, as well as $\{a,b,c,d\} \rightarrow \{a,c,d\} \rightarrow \{a,c\}$). So, our algorithm will need to exclude non-unique subset candidates from the collection; either as the power set is being populated or by removing duplicates after the entire collection has been formed.
Motivation and next step
This second procedure for generating power sets we'll call "our Recursive approach"1. While our Recursive approach may lack the directness and efficiency of the Binary Mask algorithm, we hope that coding it will at least prove to be an instructive, "chops-building", exercise in recursion, if no other utility can be found for it in the future.
Before we can implement either algorithm, however, we need to investigate the behavior of Python's set() class. Specifically, if it suffices for our purpose of containing subsets within an all-encompassing superset, in our case: the power set.
[Spoiler alert... it doesn't.]
The Python set class
The set class in python takes only immutable types (e.g. strings, numeric values, and tuples) as members. Under the hood, a set() object retains a hash or pointer to an immutable object that is a member.
Something to notice: the ordering of elements in the set's output string does not match their ordering in its definition. Unlike Python's iterable list() class, set() objects do not retain member ordering.
When you try to insert a mutable type, lists or dictionaries for example, Python will spit back an 'unhashable' type error.
Now, because separate instances of a class are allocated their own locations in memory, they are hashable; even if they contain unhashable values as attributes. And, even if the values of the attributes of the two instances are equivalent.
In [6]:
classAdvisor():def__init__(self):self.val={'Presidential','pardon'}# Attribute contains unhashable setRogerS=Advisor()# has set for attribute .valPaulM=Advisor()# has same set as above for its attribute .valmodelCitz=set([PaulM,RogerS])# include the two instances as members of a setprint(type(modelCitz))# c is indeed a setprint([type(el)forelinmodelCitz])# members of the set are instances of Advisor classprint([type(el.val)forelinmodelCitz])# attributes of member instances are sets
We adopted the above definition from Max Bernstein's blog. Also, we can instruct that instances of the class, when called, define themselves as their .val attribute (Bernstein, 2019).
In [7]:
classAdvisor():def__init__(self):self.val={'Presidential','pardon'}def__repr__(self):# method to generate representative code stringreturnself.val.__repr__()# return __repr__ code string for the# Advisor().val attributeMichaelF=Advisor()noHarmDone=set([MichaelF])noHarmDone
Out[7]:
{{'Presidential', 'pardon'}}
A quick look might suggest that we bypassed set()'s exclusion of mutables here. But don't be fooled. While we have the appearance of having a set object contained within another set object, what we actually have is a set that contains a hash to an instance of Advisor() that has a set as an attribute.
In [8]:
print(type(noHarmDone))# Notice that set()'s lack of indexingprint(type(list(noHarmDone)[0]))# methods can be a bit print(type(list(noHarmDone)[0].val))# of a pain..!
The skeptical Python programmer at this stage is likely asking her/his/them-self: "why don't you just use a list object rather than defining a whole 'nother class for cryin' out loud!?!" Number 1, lists are not hashable; for our power set generation routines to come, we require a container that is. Number 2, lists permit duplicate entries; enforcing member uniqueness would require more coding. Finally, number 3, lists preserve element ordering; while not a deal-breaker for our purposes, lists do not mathematically qualify as sets for this reason and others.
Plan for part two
In part two, we'll define a new class, ModSet(), that will behave much like Python's set() class, but with an added set-valued attribute. Our ModSet() class will employ the same approach just demonstrated above: use of a hashable class instance to contain unhashable set objects. With these container instances themselves eligible for membership in a super-set() object. Use of ModSet objects will allow us to form an all-encompassing power set that--indirectly--has sub-set() instances as members. More than a cosmetic device, defining a set container class in this way will allow the power set of a given set object to be generated using Binary Mask and Recursion-based algorithms later on in part three.
1While the writing this series, we learned of other recursive algorithms for generating the power set. In a future post, we will investigate and implement one of these, that, unlike above, does not produce subset duplicates in the process.
If you’ve set up your own host to park your WordPress site, you probably want to be able to upload and install additional files for updates, plugins and themes. While WordPress’s File Transfer Protocol (FTP) client suffices for such transactions, FTP, in its most basic form, sends login information (i.e. username and password) in plain-text to connect client and server. When FTP connections span over the internet, unencrypted login information can pose a serious security risk to your WordPress site. The worst result being an unauthorized user taking control of your host server.
I for one, dear reader, would not want this to happen. And I very much doubt that you would either.
The Solution:
Thankfully, WordPress also supports FTP over SSL, also known as FTP-Secure or FTPS. As an extension of FTP, FTPS encrypts both commands (e.g. login information) and content (file data) in transactions across networks. Encryption shields the information from network eavesdroppers who could otherwise glean usernames and passwords being sent across when you’re connecting to your host server with an FTP client.
You can set up the Very Simple FTP daemon (vsftpd) to run FTPS on your host server to move, copy, and remove files. Here we show, step-by-step, how to configure vsftpd to establish an implicit FTPS connection with WordPress’s FTP client. Further, we set up vsftpd to run in passive mode so it will be compatible with different client configurations. Using FTP-Secure, your login information and file content will stay out of view from prying eyes when you need to update or alter WordPress.
By the way, SSL stands for Secure Socket Layer; it is the cryptographic protocol for encrypting FTP transaction data. SSL has been obsolete3 for some time now, so we will use its successor, Transport Layer Security (TLS), that is also supported by FTPS in vsftpd.
1. Install vsftpd (if necessary)
First, log into a terminal as a non-root user with sudo privileges. In case vsftpd is missing from your Ubuntu LAMP installation, you can install it with the apt-get install command
sudo apt-get install vsftpd
It’s always a good idea to save the configuration file in its original form prior to making edits.
$ sudo cp /etc/vsftpd.conf /etc/vsftpd.conf.orig
We’ll make changes to, and later activate, vsftpd.conf. In addition, the unaltered version vsftpd.conf.orig, we’ll keep for reference in case our edits get out of control.
2. Set Host Firewall for passive FTPS
For FTPS to function in passive mode, you need to open a few ports in the server firewall. First things first, you need to check that your firewall is presently active.
sudo ufw status
In this example case, as it stands right now, only the port for OpenSSH is open:
OutputStatus: active
To Action From
-- ------ ----
OpenSSH ALLOW Anywhere
OpenSSH (v6) ALLOW Anywhere (v6)
Above is just and example. Your firewall rules list may look different depending on your server setup. At this point, we need to add rules for FTP traffic.
We’ll need to open port 21 for FTPS login and commands. Port 990 is default for TLS, but WordPress appears to use port 21 exclusively, so we’ll stick with that one. Finally, the range of ports 40000-50000 we choose to open for passive mode; these values must be reproduced exactly for the pasv_min and pasv_max range within vsftpd.conf:
The WordPress process runs under user www-data on your host; it is the account Apache uses to interact with files and processes server-side. Consequently, www-data should NOT be granted unfettered access to files on your server. Instead, ownership of WordPress site files should belong to another local user on your server; preferably one who does not have sudo privileges. In our case, we choose user, servusr as an example. And in this configuration, servusr will own WordPress site files on the host. Here, we use the nano text editor to add servusr to vsftpd’s list of local users to be granted FTP access.
$ sudo nano /etc/vsftpd.userlist
Simply add “servusr” to the first blank line available. If you need other users to make FTPS connections, include their usernames as well, inserting each username on its own separate line. Here’s an example.
List of example users that will be granted access via vsftpd.userlist.
Once done, save and exit.
We will include the path to this file in vsftpd.conf later in step 5.
In addition to the owning user, you might also want to define a group of users that can access WordPress files as well. For our example here, we create user group wp-admins and then add each of the host users that we would like to include.
$ sudo groupadd wp-admins
$ sudo usermod -a -G wp-admins servusr
$ sudo usermod -a -G wp-admins user1
$ sudo usermod -a -G wp-admins user2
One thing to keep in mind: the more users with admin access, the greater potential there is for conflict and security breaches. It is best to keep the number of site administrators to a minimum. Using chmod g+w {wordpress directory}, you can toggle directory/file write permissions for users in wp-admins as necessary. We’ll show how to do this later on in step 7.
4. Server SSL cert and key
Find and copy the paths your the SSL certificate and key files on your host. If you do not already have a cert and key, you can generate self-signed versions and save the results in /etc/ssl/private/ or /home/servusr/.ssl/ depending on your preference. See below two examples of server CA-certificate configuration
/etc/ssl/private/vsftpd.pem # cert and key bundled in .pem
We will paste the first example in the SSL section of vsftpd.conf in step 5, Configure SSL.
5. Edit vsftpd configuration file
In configuring vsftpd, we comment or uncomment directives in vsftpd.conf. Comments are preceded by #; text that follows on the same line does not affect vsftpd functionality. FYI: In addition to disabling unwanted directives, comments are there to help us, the human users, remember what does what and why–especially when we come in back six months and we need to figure out how to alter how vsftpd runs. Many directives we will leave commented out as they are not required for our setup.
Specify command port
Use IPv4 protocol, listening on port 21. WordPress does not appear to use the default port 990 for FTPS connections.
# Run standalone? vsftpd can run either from an inetd
# as a standalone daemon started from an initscript.
listen=YES
listen_port=21
Do not allow folks to log in anonymously, however do allow some users that have a local account on the server. [The directive to check a user list for granting access is below.] Of course, WordPress requires write access to certain files and directories for updates.
Access control
# Allow anonymous FTP? (Disabled by default).
anonymous_enable=NO
#anonymous_enable=YES
#
# Uncomment this to allow local users to log in.
local_enable=YES
#
# Uncomment this to enable any form of FTP write command.
write_enable=YES
The daemon will grant access only to local users that are included in vsftpd.userlist. You should have already generated this file in step 3 above. If not, use your favorite text editor (e.g. nano) in a separate terminal and sudo save as /etc/vsftpd.userlist. Be sure to include your local user (e.g. servusr) in the list.
# Allow only certain users to log into the FTP server; local
# users that are included in vsftpd.userlist
userlist_enable=YES
userlist_file=/etc/vsftpd.userlist
userlist_deny=NO
Specify file permissions policy
WordPress requires that group be able to read directory contents and files. Therefore, we will uncomment the local_umask=022 line. If you would like users in group wp-admins to have write access as well, set local_umask to 002.
# Default umask for local users is 077. You may wish to change
# this to 022, if your users expect that (022 is used by most
# other ftpd's)
local_umask=022
Transaction feedback
The three directives that follow are not needed for FTPS, I’ve activated them to give the user feedback on file transactions.
# Activate directory messages - messages given to remote users
# when they go into a certain directory.
dirmessage_enable=YES
#
# If enabled, vsftpd will display directory listings with the
# time in your local time zone. The default is to display
# GMT. The times returned by the MDTM FTP command are also
# affected by this option.
use_localtime=YES
#
# Activate logging of uploads/downloads.
xferlog_enable=YES
Leave the next two directives as they are from the the default configuration.
# This option should be the name of a directory which is empty.
# Also, the directory should not be writable by the ftp user.
# This directory is used as a secure chroot() jail at times
# vsftpd does not require filesystem access.
secure_chroot_dir=/var/run/vsftpd/empty
#
# This string is the name of the PAM service vsftpd will use.
pam_service_name=vsftpd
Specify passive FTP mode
The next section specifies that FTP will run in passive mode, using ports in range 40000 to 50000 for data transfer.
# We'll limit the range of ports that can be used for passive
# FTP to make sure enough connections are available.
pasv_enable=YES
pasv_min_port=40000
pasv_max_port=50000
pasv_promiscuous=YES
dirlist_enable=YES
Configure SSL
We’re in the home stretch now. In this last section we configure vsftpd to run in SSL.
To establish a secure socket, we need to specify the path to your server’s CA-certificate and key. Below is shown an example clause for this in which the cert and key are both contained within a .pem file as discussed in step 4.
# ##### SSL Config ######
# This option specifies the location of the RSA certificate to
# use for SSL encrypted connections.
rsa_cert_file=/etc/ssl/private/vsftpd.pem
rsa_private_key_file=/etc/ssl/private/vsftpd.pem
ssl_enable=YES
Below we instruct that vsftpd must encrypt both login information and file data. For security, vsftp daemon will deny anonymous connection requests.
# Explicitly deny anonymous connections over SSL and to require
# SSL for both data transfer and logins:
allow_anon_ssl=NO
force_local_data_ssl=YES
force_local_logins_ssl=YES
The daemon should encrypt using TLS only, not SSL.
# We'll configure the server to use TLS, the preferred
# successor to SSL by adding the following lines:
ssl_tlsv1=YES
ssl_sslv2=NO
ssl_sslv3=NO
Lastly, we need to include two more specifics about SSL functionality: not to require that FTP clients reuse SSL connections and SSL keys be at least 128 bits long. In case you’re wondering, rationale for these directives can be found here1.
# Do not require SSL reuse because it can break
# many FTP clients
require_ssl_reuse=NO
# Require "high" encryption cipher suites, which
# currently means key lengths equal to or greater
# than 128 bits:
ssl_ciphers=HIGH
Final step: Save and Exit
At this point we’ve completed edits to our configuration and we’re ready to restart vsftpd. In your editor, which you opened under sudo, save the file as /etc/vsftpd.conf and exit back to the command prompt. Now we’re ready to move forward.
6. Restart vsftp daemon and check status
With the configuration file now saved, you now need to restart the vsftp daemon for the changes to take effect. At the prompt, enter
$ systemctl restart vsftpd
to restart and
$ systemctl status vsftpd
to verify that the daemon has in fact restarted and is up and running as expected. Status output should show
$ systemctl status vsftpd
● vsftpd.service - vsftpd FTP server
Loaded: loaded (/lib/systemd/system/vsftpd.service; enabled; vendor preset: e
Active: active (running) since Mon 2021-01-04 03:36:57 UTC; 3h 12min ago
Process: 14878 ExecStartPre=/bin/mkdir -p /var/run/vsftpd/empty (code=exited,
Main PID: 14882 (vsftpd)
Tasks: 1 (limit: 1151)
CGroup: /system.slice/vsftpd.service
└─14882 /usr/sbin/vsftpd /etc/vsftpd.conf
in the event of a successful restart.
7. Set directory ownership and permissions
In this important step, we navigate to where our WordPress application files are stored. We need to make sure certain directories are accessible to servusr, our WordPress FTP user, and soon to be owner, of WordPress files. An example might be
$ sudo cd /var/www/site.directory/wordpress
or perhaps
$ sudo cd /var/www/site.directory/blog
depending on your server’s setup. Once you’re in the directory, you need set up ownership of certain sub-directories so that FTP can modify them. So first, we’ll change their owner and access group with chown command
where servusr is the username of a local user on the host server who has FTP access in vsftpd. It will be through servusr that changes to wp-content will be made. For security, do not assign ownership of any WordPress directories or files to the generic Apache user www-data. Doing so enables visitors the ability to modify your site without your say so.
Now, if you do need www-data to be able to write to these directories, I suggest adding www-data to the wp-adminsgroup (see step 3 above), and then grant the group permission to write. To do this, change group write permissions with chmod
$ sudo chmod g+w . # wp-admins group can write to parent dir
$ sudo chown g+w ./wp-content
$ sudo chown g+w ./wp-content/uploads
$ sudo chown g+w ./wp-content/plugins
$ sudo chown g+w ./wp-content/themes
Though it seems to me that granting www-data write access–even indirectly through group membership as above–still puts WordPress at risk. And based on other posts2 about WordPress security, perhaps this concern is valid. As you’ll see below, granting www-data write permission to the five directories complies with WordPress’s file permission expectations in the Site Health tool.
So, there’s that…
But I digress… And I’ll get down off of my soap box now. After making changes to directory permissions, we need to restart Apache for them to take effect.
$ systemctl restart apache2
$ systemctl status apache2
You’ll be prompted to type in your password for the restart request.
8. Verify write status of directories
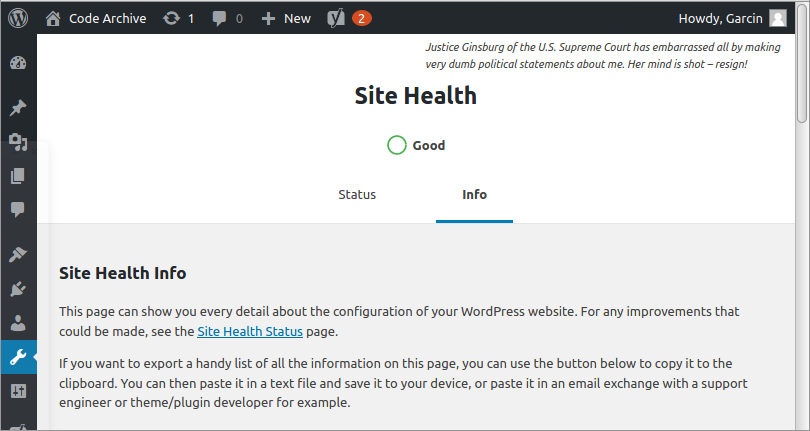
Now that you have restarted Apache, the five directories, whose ownership and permissions we modified above, should now be writeable. And we can check this using the Site Health tool in the WordPress dashboard. To do this, log in to the administrative dashboard by entering the following URL into a browser
https://your.wp.domain.name.com/wp-admin
Put in the username and password for your site’s admin user, log in, and navigate to Tools -> Site Health.
Opening the Site Health screen in WordPress dashboard.
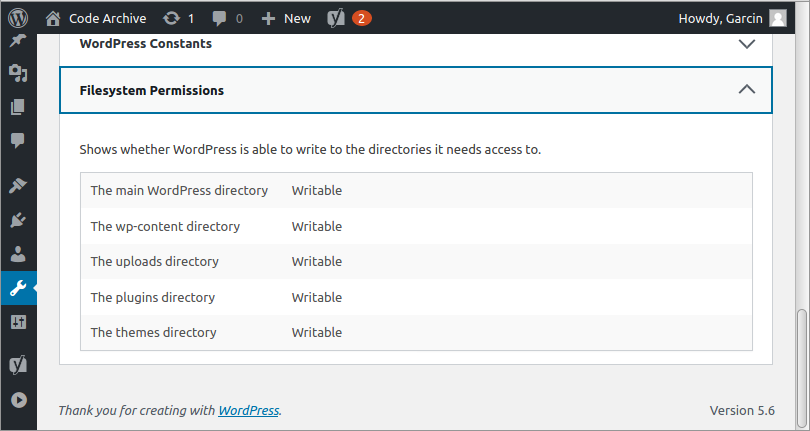
Selecting the “info” tab brings up a list of diagnostic categories. Scroll down an select the bottom-most pull out, named “Filesystem Permissions”. Listed are the five directories from above, and also whether or not they are “Writeable” by WordPress. If you did decide on granting write access to the group of which www-data is a member, your screen should appear as follows:
“Writeable” shows that we correctly set up directory ownership to support file uploading.
If all five are indeed writeable, you’re all set to try a plugin installation to verify your FTPS setup. Alternatively, if they show up as “Not Writeable”, likely the result of NOT granting write permission to the wp-admins group (of which www-data is a member), you should still be able to install a plugin. As long as you use the owner account of the files (e.g. servusr) to establish your FTPS connection, you should be able to access and modify the filesystem as needed.
9. Add new plugin
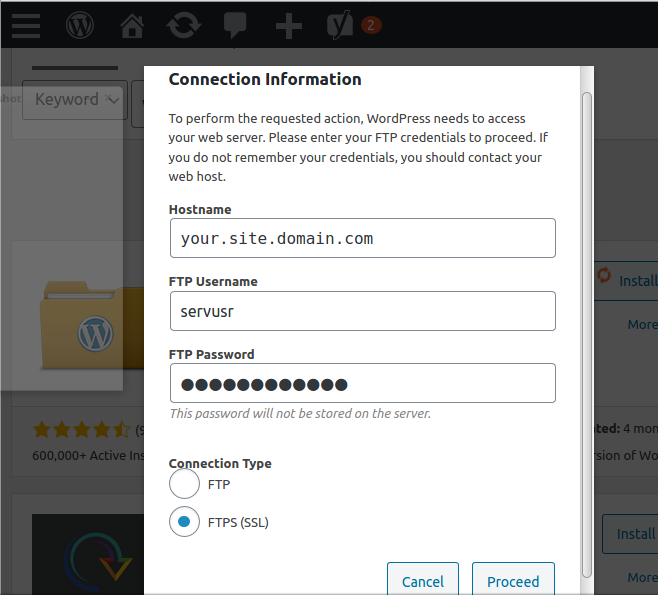
At this stage your can navigate to the add plugin page, select an innocuous one, like, Hello Dolly, and hit install. The login page for WordPress’s FTP client should appear.
Example credentials for FTPS supported plugin installation
Enter your login credentials, toggle to “FTPS (SSL)”, and hit proceed. And now, please feel free to hold your breath, cross your fingers, or say a little prayer as the progress arrows churn. I always do.
If successful, you’ll see the green check mark beside “installed!” appear in the button. You’ve done it! Now you can install files into WordPress using FTP over SSL/TLS. You can rest a little easier knowing your site has one less security hole.